
Will Ice Lake be able to compete with AMD’s latest-generation CPU, Milan? More importantly, will Intel’s market position in data center computing change due to the NVIDIA/Arm attack?
Omdia view
Summary
In April 2021, Intel launched its 10nm Ice Lake CPU family, marketed as 3rd Gen Intel Xeon Scalable processors. While the lower process node and design changes will drive better CPU performance compared to Intel’s prior generation, it does not look like Ice Lake CPUs will be setting any benchmark records. As such, the launch of Ice Lake is not competitively significant. Rather, it is a way to “bridge the gap” until Intel’s 7nm Sapphire Rapids CPUs arrives in 2022. In fact, it is Intel’s new archnemesis, NVIDIA, that is shaking the cloud and data center ecosystem with the announcement of its first CPU.
Will Ice Lake be able to compete with AMD’s latest-generation CPU, Milan? More importantly, will Intel’s market position in data center computing change due to the NVIDIA/Arm attack?
Thought leadership across the board but performance leadership in AI, HPC, and security only
Intel responded to four inflection points when developing Ice Lake:
- The shift to hybrid cloud is growing and democratizing scale and efficiency.
- Artificial intelligence (AI) and machine learning (ML) are becoming infused in every data center application, from the edge to the cloud.
- 5G is fueling growth in workloads that require low latency and high bandwidth.
- Compute is moving closer to the edge, where data is created and consumed.
While the validity of these trends is indisputable, Ice Lake hardly addresses all four points directly. The improvement in performance, compared to Cascade Lake, is more of an indirect response to these trends. The only specific engineering improvement in the Ice Lake design is the addition of dedicated AI accelerators. As a result, Omdia expects Ice Lake to appeal most to enterprises running AI workloads, particularly inferencing, without a co-processor.
Key CPU architecture design points and gen-on-gen improvements include the following:
- Support for 1- to 8-CPU server configurations
- Higher memory bandwidth (up to 8 channels of DDR4-3200 per CPU)
- New core architecture
- Increased number of processor cores (up to 40)
- More system memory (up to 6TB capacity per socket)
- Faster input/output (up to 64 lanes of PCI Express 4 per socket)
- Built-in AI and encryption acceleration
Coupled with Intel’s Deep Learning Boost (DL Boost) technologies, Ice Lake’s built-in AI accelerator offers significantly better performance than AMD’s Milan in specialized benchmarks like language processing, object detection and image classification, and recognition.
DL Boost is an umbrella term for features technologies like AVX-512 Vector Neural Network Instructions (VNNI), an instruction set extension that enables reduced-precision (8-bit and 16-bit) multiply-accumulate for acceleration of inference. With DL Boost, Intel estimates Ice Lake can achieve the following:
- 74% inference throughput increase over Cascade Lake
- 50% higher average AI performance across 20 workloads over AMD’s Milan
- 30% higher average AI performance across 20 workloads over NVIDIA’s A100 GPU
Beyond AI and a few specific high performance computing (HPC) and security workloads, expect Ice Lake to fall behind AMD’s Milan. On a socket-by-socket basis, Milan just has significantly more cores: 64. To avoid losing too much share to AMD, Intel will have to rely on software optimization and decade-long relationships, putting its 12,000 software engineers and army of salespeople to work. This strategy worked in 2019 and 2020, so Omdia expects it will help Intel avoid big share losses.
And poor yields
Ice Lake may be Intel’s last monolithic architecture, and getting high yields will be tough. It is a well-known semiconductor fact that the introduction of a lower processor node is typically associated with lower wafer fabrication yields. A single defect can eliminate the usability of a whole area of the wafer. During the maturation of the production process, faults get reduced. Intel has publicly discussed the impact of this “learning curve” in determining process availability.
Figure 1: Wafer fabrication process – working vs. defective dies
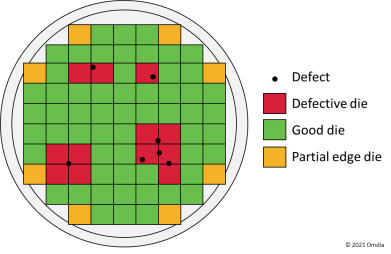 Source: Omdia
Source: Omdia
As a rule of thumb, the larger the measurements of die required to build a processor, the higher the chance of a defect and the higher the cost of the processor. The monolithic design of Ice Lake, using a single large die, means very few working processors will come out of each wafer. By comparison, AMD’s Milan is made up of four dies “glued” together with superfast interconnect. This is the direction Intel is likely to pursue with its next-generation CPUs, Sapphire Rapids, but Omdia does not expect them to hit the market before the end of 2022. We do, however, anticipate Intel will raise prices gen-on-gen by 20–30%.
Then along came Grace
So far, this analyst opinion has discussed how Ice Lake beats Milan in AI and HPC but falls short in core count and price. Intel’s engineers have been very inventive in developing and improving the DL Boost features, and it will take AMD time to catch up. It looks like NVIDIA will be the real long-term CPU threat in the AI and HPC domain.
The GPU vendor came out with a bombshell announcement that it will enter the CPU arena with a new CPU, called Grace, which NVIDIA says is designed for giant-scale AI and HPC applications. Grace is based on Arm’s next-gen Neoverse cores. It puts Arm’s v9 architecture to work, as discussed in Omdia’s analyst opinion, Armv9: The next Arm offensive.
The Grace CPU will ship on a board, integrated with an NVLink interconnected GPU, with 900GBps connection between the CPU and GPU. This will result in an estimated 30x higher aggregate bandwidth compared to today’s best servers, according to NVIDIA. Grace will also utilize the LPDDR5x memory, a new memory standard currently adopted in mobile devices only. The LP in the acronym stands for “low power,” and LPDDR5x will deliver 10x better energy efficiency compared to DDR4, according to NVIDIA. Additionally, the Grace design will produce unified cache coherence with a single memory address space, combining system and high bandwidth memory (HBM) GPU memory and simplifying programmability.
A key downside to new processors is the lack of software support. NVIDIA has indicated it has ensured Grace will be supported by the NVIDIA HPC software development kit and the widely adopted CUDA and CUDA-X libraries.
Performance-wise, NVIDIA has indicated Grace-based servers will be 10x faster in AI training compared to the DGX servers that lead the industry today. The CPU will be available in early 2023, just in time to compete with Intel’s Sapphire Rapids.
Bottom line: It is all about Grace
With leading performance in only a few niche workloads, Ice Lake is set to be a stopgap measure while the industry waits for Sapphire Rapids. Limited availability due to likely yield issues and higher prices will obstruct Intel from competing fiercely with AMD in the next 12–18 months.
The blue giant’s strategy is clear—weather the storm until its big break. Unfortunately, NVIDIA’s entry into the CPU arena could prove impactful in taking away Intel’s performance leadership in AI. Couple that with a competitive roadmap from AMD and an increasingly long list of Arm-based CPU vendors, and Intel is in trouble. The question is: Will Sapphire Rapids be enough?
Appendix
Further reading
Arm v9: The next Arm offensive (April 2021)
Authors
Vlad Galabov, Research Director, Cloud and Data Center Research Practice
Greg Cline, Principal Analyst, Cloud and Data Center Research Practice
Manoj Sukumaran, Senior Analyst, Cloud and Data Center Research Practice

